Incident vs. Service Request: From Theory to Practice
Discover how incidents and service requests differ in ITIL and why the distinction is vital for IT service management success.

Discover how incidents and service requests differ in ITIL and why the distinction is vital for IT service management success.
In IT support two terms often cause confusion among both users and IT professionals: Incident and Service Request. At first glance, they may look similar—both arrive at the service desk as “tickets,” both require attention, and both involve end users. Yet, ITIL best practices treat them as separate processes, with distinct goals, workflows, and success criteria.
While the difference between the two terms seems vague, it actually affects a lot. If everything is treated as an incident, teams risk overloading escalation paths and mismanaging priorities. If service requests are not properly defined, employees won’t know when to expect resolving, leading to frustration and unnecessary follow-ups. Which leads to extra notifications and status checks, which, in turn, increase the workload on the IT team.
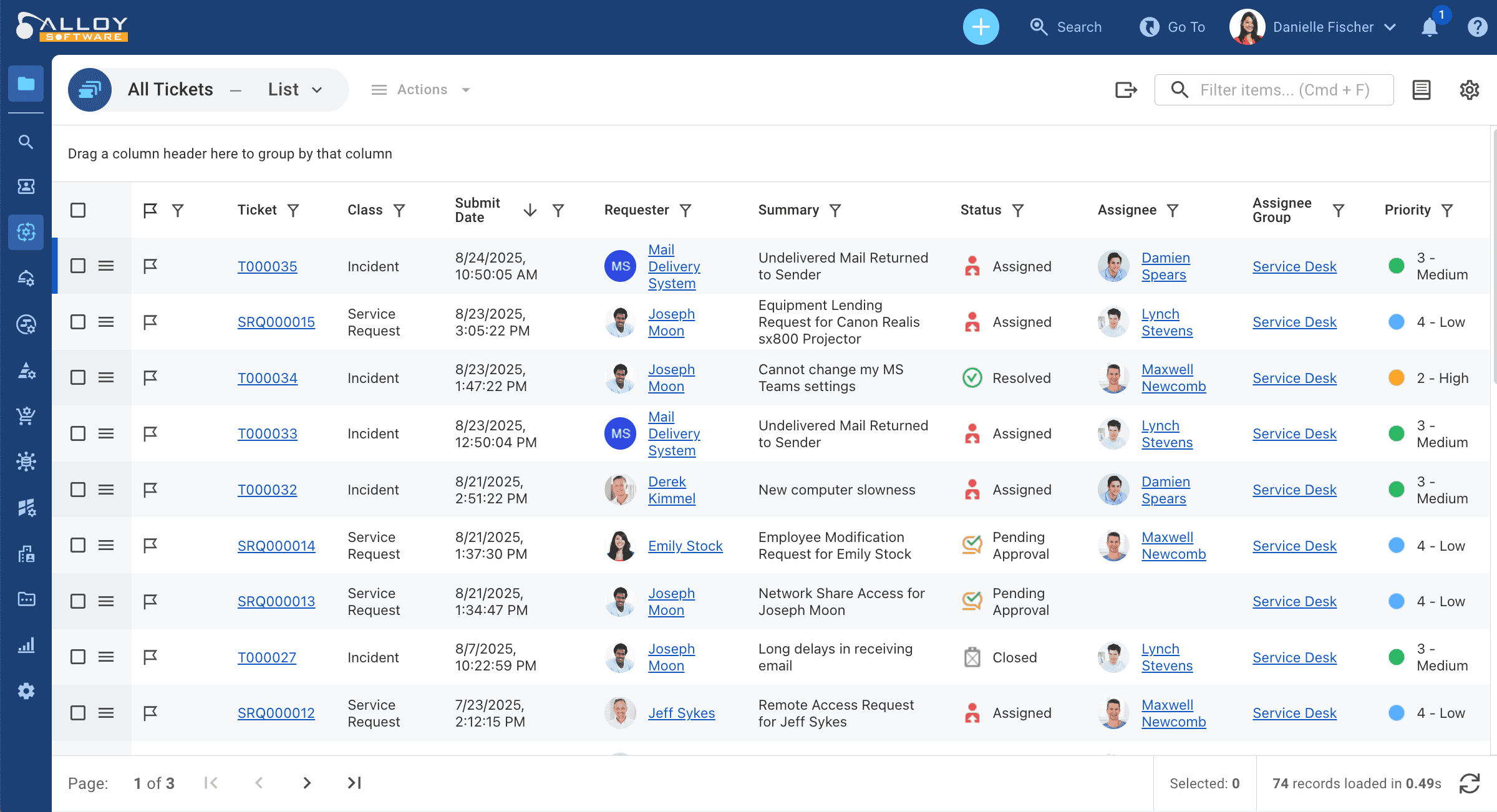
The All Tickets grid in Alloy Navigator displays records of all Service Desk Tickets, which include: Incidents, Problems, Change Requests, Service Requests, Work Orders.
Let’s explore what sets incidents apart from service requests, why this distinction matters, and how it can improve efficiency, user satisfaction, and the overall quality of IT services.
ITSM (IT Service Management) is a broad philosophy and operational approach that defines how IT should operate to deliver a quality service for their customers—whether they are employees inside the organization or external clients.
Instead of viewing IT purely as a technical support department that reacts to problems, ITSM positions it as a service provider with defined processes, service quality targets, and a focus on delivering consistent value to the business.

The main goal of ITSM is to transform an IT department viewed as a “repairman” into a service organization with clear quality standards.
ITIL is a set of best practices for organizing ITSM.
ITIL is not a company, not a product, and not software, but a methodological base.

ITIL is a collection of best practices for IT organizations. Its purpose is to formalize IT processes and establish a structured approach to managing them. ITIL covers the full lifecycle of IT services, from their initial design and deployment to day-to-day operations, service improvement, and eventual retirement. It describes how to handle incidents, service requests, change requests—from the moment they arise to their resolution.
At first glance, implementing ITIL may seem unnecessarily complex and not worth the cost. However, in practice, its gradual adoption in IT operations often results in significantly less chaos, improved coordination between teams, and more predictable outcomes. Over time, organizations that implement ITIL typically see measurable improvements in key performance indicators such as average response time, average resolution time, and user satisfaction, thanks to faster response times, consistent quality of execution, and better communication.
ITIL’s definitions of these two concepts might help understand the difference.
Incident is an unplanned interruption of an IT service or a decrease in its quality.
According to ITIL, any event that disrupts the normal operation of a service is an incident.
Examples:
The main goal of the IT team when processing incident is:
To restore the service as quickly as possible to minimize the impact on the business.
On the other hand, a planned, routine request from a user to obtain information, access, or perform a repeatable service that is not related to an incident, is a service request.
Examples:
The goal of the IT team when processing service requests is:
To fulfill the request within the agreed procedures and SLAs.

Follow us on LinkedIn for the latest product insights, feature previews, and more exclusive updates.
Here’s how ITIL distinguishes incidents from service requests:
With Alloy’s built-in Service Catalog Software, routine service requests (like password resets, hardware provisioning, or onboarding) can be fully automated and monitored within SLA boundaries. The platform supports multi-step approval chains, custom-designed workflows, and real-time visibility to optimize delivery—no matter how many steps or stakeholders are involved. Plus, post-request user satisfaction can be measured directly, helping teams continuously refine their service offerings.
Failing to clearly separate incidents from service requests can slow down IT operations, misdirect resources, and frustrate end users. Here’s why getting it right is critical:
Whether it’s a minor password change request or a major outage, Alloy Software’s All-in-One ITSM & ITAM Platform ensures that your incident resolution process is never left to chaos. The self-service portal enables end-users to log incidents and find instant solutions, while automation rules route issues to the right experts and trigger predefined remediation actions. Built-in reporting, real-time dashboards, and integrated knowledge bases keep your team one step ahead, ensuring every incident—no matter its complexity—gets resolved faster, with fewer errors and maximum efficiency.
In ITIL, the distinction between incidents and service requests is more than a theoretical exercise—it’s a practical necessity for delivering reliable IT services. When organizations can differentiate these processes, they gain clearer SLAs, faster resolutions, more predictable fulfilment, and ultimately higher trust from employees and customers.
By applying ITIL’s best practices step by step, companies can reduce downtime, streamline request handling, and free up technical teams to focus on what matters most. The result is a more resilient IT service desk, capable of supporting business growth without falling into chaos.
Now that we’ve explored how incidents differ from service requests and why this matters, the next step is clear: review your own ITSM processes, identify where the two may be mixed up, and start building a framework that works smarter, not harder.